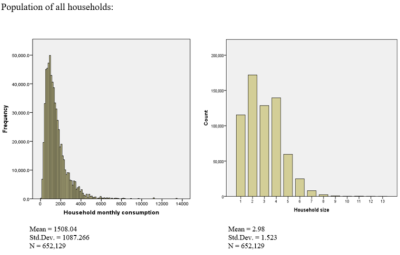
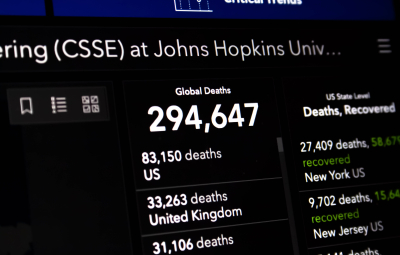
Artificial intelligence (AI) refers to a bunch of computer algorithms used to build machines capable of carrying out tasks that typically require human intelligence. These machines learn particular tasks based on the data we generate. Similar to an old saying “We are what we eat,” the performance of an AI system depends on how and what we “teach” it. Thus, the data collected and used are fundamental to training AI systems.
Recommendation systems, precision medicine, and many other popular customized services rely on accurate information acquired or processed via data analysis. For example, when a person uses Google to search for information about a topic, the site displays results based on the individual’s use history and data analyzed by Google’s systems. Humans live in a data-driven world. Data generated by people and systems, combined with information technology, are now the foundation for creating effective strategies for success in enterprise. Kambhampaty, a Forbes Councils Member, pointed this out in “It’s All About Data“ (Forbes, July 23, 2018).
However, using all available data directly may be too aggressive, since data can be contaminated and biased. How to select good “representative data” is always the essential issue for building a successful information service – in medicine, business, scientific research, and so on. Cédric Villani, a mathematician, French Parliament member, and 2014 Joseph L. Doob Prize winner, observed the following in his book For a Meaningful Artificial Intelligence:
The benefits of data, which are central to developments in AI, are currently enjoyed by a set of a few major stakeholders who tend to limit their capacities for innovation to their ever more powerful enterprises. It will only be possible to redress the balance of power by extending the circulation of this data; this would benefit not just public authorities but also the smallest of stakeholders in the economy.
Yes, it is all about data. As statisticians, we welcome data sets with large sample sizes, but we never really require that they be infinitely large – a designation that is merely a justification for collecting large samples. When we use “good representative samples,” we can justify building models that fit the given data reasonably well under certain conditions, and that make interpretation easy. Thus, scientists are taught to avoid overfitted models which are usually complicated and difficult to interpret — and based too much on the observed data that they tend not to do well predicting for new situations. However, industry AI systems use accessible data to train complicated models, which then always overfit the collected data. And, to use all available data, researchers might ignore how the data were collected and whether they actually represent a population the company is interested in.
How useful are available data to the ultimate goal? How can we be misled, even with large amounts of data? Conventional statistical methods, under model assumptions, require high quality data for the final results to not be misleading because of bias or contamination in the data, and they usually make use of smaller data sizes than the modern IT methods (e.g., machine learning and deep learning). In conventional statistical modeling, use of statistical information criteria to measure predictive abilities is usually computational feasible when sample size is not extremely large. However, modern IT methods rely on very big data sets, where measuring aspects of the quality of data going into the algorithms becomes impractical.
Convolutional neural networks, a very popular deep learning method, are designed for dense data. When data used for training is dense in the population of interest, overfitting will not be an issue. However, sparse data are common in many applications, and naively using the sparse data to train an AI system will definitely jeopardize the usefulness of methods designed for dense data. Jaritz, et al (2018), in one of their technical reports, tried to solve the sparse data issue for image and vision data, which are usually sparse. But, their method seems an ad hoc solution, and it remains unclear how to address the problem in other applications.
Language models are commonly used in speech recognition, machine translation, optical character recognition, and so on. In language applications, researchers face a similar sparse data issue, since language models can be culture dependent. From Lera Boroditsky’s TED talk, How language shapes the way we think, we can learn how difficult data collection and processing can be in language research. Bender et al. (2021) presented a paper titled On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? at FAccT ’21: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (March 2021, pp 610–623). The authors “take a step back and ask: How big is too big?” and “What are the possible risks associated with this technology and what paths are available for mitigating those risks?” Additionally, a workshop recently organized by Critical AI@Rutgers, titled “Data-centrism and its discontents: Workshop #1” continues the discussion about the ethics of data curation. Although their focus is on language models, similar issues are found in many areas. The popularity of machine learning and deep learning in nearly all fields makes it essential to consider the ethics of data curation.
Indeed, we usually prefer large data sets for analysis, but size is not the only factor considered relative to usefulness or quality. In an article published in Science “Adversarial attacks on medical machine learning,” Finlayson et al. (2019) observed that manipulations of only tiny amounts of digital data can change the behavior of AI systems. Specifically, “the researchers demonstrated that, by changing a small number of pixels in an image of a benign skin lesion, a diagnostic AI system could be tricked into identifying the lesion as malignant.” They presented an example to illustrate how it can be done, and said that “This ‘adversarial noise’ was iteratively optimized to have maximum disruptive effect on the model’s interpretation of the image without changing any individual pixel by more than a tiny amount.” Mets and Smith then published an article in The New York Times (March 21, 2019) titled “Warnings of a Dark Side of A.I. in Health Care,” in which they pointed out that AI systems built on neural networks, or other similar complex mathematical or statistical tools, can learn tasks from large amounts of data, but may carry unintended consequences — even though “Ideally, such systems would improve the efficiency of the health care system.” Likewise, in the article “AI-Driven Dermatology Could Leave Dark-Skinned Patients Behind” (The Atlantic, August 17, 2018), Angela Lashbrook said that “Machine learning has the potential to save thousands of people from skin cancer each year—while putting others at greater risk.” Adversarial attacks in AI and deep learning systems are the subject of intense discussion; more examples can be found in “Attacking Machine Learning with Adversarial Examples,” OpenAI Codex (February 24, 2017).
Although the situations in other fields may differ from those surrounding language and image models, we should still ask the same questions. Training an AI system to apply an algorithm accurately requires a lot of data, but again – “How large is large enough?” Collecting representative data is even more difficult than collecting a lot of data.
Classical statistical modeling has shown that these issues are context and model dependent. “Researchers say computer systems are learning from lots and lots of digitized books and news articles that could bake old attitudes into new technology” said Cade Mets in The New York Times article “We Teach A.I. Systems Everything, Including Our Biases” (Nov. 11, 2019). Errare humanum est (to err is human); thus, the idea that AI might learn everything about us, including our biases, seems unsurprising. And this is why data curation ethics are essential when building AI systems; especially in highly culture-dependent applications such as language study.
Recently, the idea of the human-centered artificial intelligence (HAI), a system that is continuously improved using human input to provide an effective experience between human and machine, has become popular. HAI may offer a promising compromise to respond to the issues I mention here.
All these discussions remind me of Albert Einstein’s address to the student body of California Institute of Technology, in 1931 (see “Einstein Sees Lack in Applying Science”, The New York Times (February 16, 1931)”:
It is not enough that you should understand about applied science in order that your work may increase man’s blessings. Concern for man himself and his fate must always form the chief interest of all technical endeavors, concern for the great unsolved problems of the organization of labor and the distribution of goods in order that the creations of our mind shall be a blessing and not a curse to mankind. Never forget this in the midst of your diagrams and equations.