A friend recently posted this graph from an investment company flyer as evidence that the risk of death from COVID-19 is much smaller than the mainstream media are suggesting.
The conclusion inferred is that the very small numbers, less than 20%, summarizing COVID-19 deaths as a percentage of total deaths in each age group means there is a very small risk of dying from COVID-19. Alas, this is incorrect. The graph and the small numbers do not describe the risk that a person in a particular age group will die from COVID-19 but rather the proportion of dead people of a certain age that have died from COVID-19.
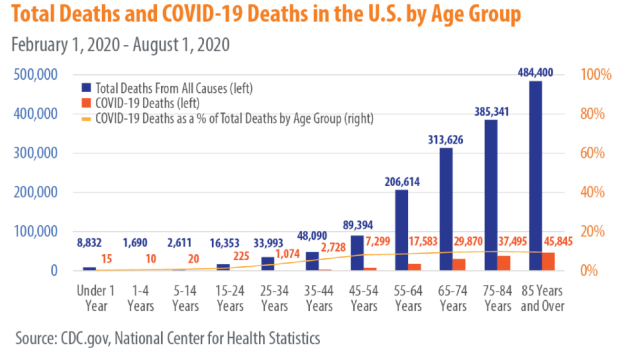
Every graph is the answer to a specific question, sometimes several specific questions. Is this graph answering the question “What is the risk of dying from COVID-19?” Nope. There is a conditional statement missing! The question this graph comes much closer to answering is “If you are dead, what are the odds that you died from COVID-19?” or rather, the data and graph are all conditional on the observed individuals being dead. These data have little to do with the question of interest to most newspaper readers and the question inferred in my friend’s original post.
There are three elements mischievously tied together in this logical slip, call it perhaps a trompe l’esprit, like the French-based term trompe l’oeil for a painting that tricks the eye, except this is a picture of data that trick the mind or the intellect. The three elements are (1) the graph, or that small number of less than 20%, is not actually the answer to the question of interest; (2) the information is interpreted as unconditional (relevant to all situations), when the data are conditional (dependent on a particular situation); and (3) the risk of interest is not clearly defined (risk of what and risk to whom).
What is the question that the graph answers?
In casual English, “What is the risk of dying of COVID-19?” is not well-specified. This makes it a bit easier to confuse things:
- The question the graph answers: “If a particular person were dead, what are the odds that they died of COVID-19?”
- The question of interest: “What are a particular person’s odds of dying from COVID-19?”
The question the graph answers does not give a reader a sense of the risk, for an average person in an age group (whoever that is should be the subject of another blog post) of dying of COVID-19. It only provides the proportion of all deaths attributed to COVID-19 by age group. While the words sound similar, the numbers describe very different ideas that are not directly related. For example, if we were able, suddenly, to cure cancer, the proportion of all deaths attributed to COVID-19 would suddenly go up (and the graph above would change), but there would be no change to most individuals’ risk of dying from COVID-19 (the question most readers want to know).
Take another example of something that is very risky, say, sticking your finger in an electrical socket. If you are dead at age 65, the odds that you died from sticking your finger in an electrical socket are very, very low (analogous to the question the graph answers). But, if you are 65 and you stick your fingers in an electrical socket, the odds of dying are unpleasantly high (more similar to the question most readers want answered).
The conditional nature of most data summaries
After years of trying to understand the world through data, things happen to statisticians. As above, we tend to reverse-engineer every graph by asking “What question is it addressing?” We also instinctively ask “conditional on what?” Much, if not all, the data we observe and summarize exist only after various events have occurred. Our interpretation of the data therefore depends on those events, which often go unspecified in news coverage, in analysis, and in casual thinking about the data.
Again, a really silly example. We could look at the odds of winning various amounts in a lottery by gender, by age, by location. Using lottery winnings per ticket, we could estimate the average amount won by women in my age in the USA versus in Italy. All this information, however, does me no good because I don’t buy lottery tickets. Using lottery winnings per ticket makes all the estimates conditional on having bought a ticket.
Of much greater interest are the serious examples. A great article in the Boston Globe, explains how Simpson’s Paradox can lead to the overall rate of deaths per police encounter in the United States appearing lower for African-Americans than for others when using certain summary statistics – even when an African-American is more likely than others to be killed by police across every type of encounter. Underlying the paradox is this notion of the conditional nature of most observations. In this case, death rates are conditional on why the police encounter occurred and there are very different odds of particular types of police encounters by race. Of course election results, a pretty gosh dang important data summary, are conditional on the probability of individual voters having gotten to the polls or having mailed in their ballots successfully.
And finally, risk.
What is the risk of dying from COVID-19? The answer to the question most readers want to know, “How likely am I to die from COVID-19?” is difficult, or even impossible, to answer in an objective way because we don’t have enough data for particular subgroups, we don’t know enough about the disease yet, and we don’t know what will happen even in the near future with respect to new treatments or viral behavior. The issue of not having enough data for particular sub-groups is intricately tied to the conditional nature of the data needed and the definition of the risk of interest.
My own risk is conditional on my own behaviors. An estimate of my risk of contracting COVID-19 would require data on many other individuals, with similar underlying health conditions as I have, choosing the same set of behaviors as I do. And then, an estimate of the risk of death, conditional on having contracted it, would have to come from sub-groups of people with similar initial health status as me who had also contracted the disease. News readers might also be interested in relative risk for even small, everyday decision-making. Relative risk quantifies the difference between risk associated with two alternatives. For example, how does grocery-shopping at a particular time of day alter my risk of contracting COVID-19 relative to getting my groceries delivered?
But, we can get a general understanding of the risk at the population scale by comparing past death rates for COVID-19 to past death rates for other high risk activities. Car accidents, for example, led to 11.2 deaths per 100,000 Americans in 12 months (2018 data). Covid-19 led to 48.1 deaths per 100,000 Americans (using 2019 USA population estimate) in the first 6 months of 2020. So, conditional on being in America, death rates from COVID-19, so far, are approximately 8x higher than death rates from car accidents. Note that this is still an estimate of the risk of a very specific outcome, death, rather than of the risk of another bad outcome.
Risks of other negative and potentially long-term health outcomes from contracting COVID-19 remain mostly unknown although an Italian study cited in a story in The Atlantic about long-term negative impacts from COVID-19 found that 87 percent of hospitalized patients still had symptoms after two months. “We cannot fight what we do not measure,” says Nisreen Alwan, a public-health professor at the University of Southampton who has had COVID-19. “Death is not the only thing that counts. We must also count lives changed.”
Statistical perspective
So, was my reaction to this graph somehow rooted in my statistical training? Odds are good that it was. I believe that a statistician’s perspective on the news and even on a single graph is often different and useful. Certainly, these days, I also wish I had a virologist perspective and an economist perspective.
I do not believe, however, that the statistician’s perspective is acquired mostly through formal training. Formal training is essential but, eventually, the statistical perspective comes from years of having made and observed many kinds of errors. And then, of having figured out what kinds of questions are most effective in de-bugging problems. Ever worked with a really good mechanic? A really good computer technician? It’s pretty much the same phenomena.
As above, statistically savvy questions can be fairly simple. Eventually, after enough statistical consulting in which graphs are designed to answer particular questions of interest, it becomes second nature for statisticians to ask themselves, “What question is this graph answering?” After making mistakes because data which seemed to be unconditional were actually conditional, it also becomes second nature to ask “On what events are these data conditional? And, how does that impact the conclusions I can draw from the data?” Finally, after endless miscommunication about risk, we learn to specify carefully, “Risk of what exactly?”




